Technology behind Kombai
Introduction
Nowadays, it is a common practice to create high-fidelity designs that can serve as a reference for developing user interfaces for applications and websites. These designs are usually created using UI design tools like Figma or Adobe XD. They consist of free-form vector images made up of layers. These tools provide UX designers with a blank canvas for creative thinking without having to worry about engineering details during the ideation phase. Once the designs are created and reviewed, developers use modern frontend technology stacks to bring them to life in code.
Modern front-end coding process can be thought of as a summation of two parts - building the visual appearance that matches a given design and building functionalities and interactions around the visual appearance-related code. In the interest of brevity, we'll refer to the visual appearance-related code as "UI code."
UI code often contains common patterns that developers with a moderate amount of experience can easily recognize. However, they still have to manually write these parts of the UI code, such as writing styles and DOMs for new components and laying out existing components in larger layouts. Developers often find these tasks repetitive & cumbersome and want to spend less time doing this.
Because of the repetitive, pattern-based nature of these tasks, we think it might be possible to train models - colloquially often called “AI” in the post-GPT world - to do a significant part of these. Our objective is to develop such models that can assist developers with these repetitive tasks.
Challenges
After attempting to use existing image recognition and large language models for this task, we realized that the primary challenge in generating meaningful code from UI designs lies in interpreting the designs intelligently, as a developer would. To write UI code, developers rely on their experience, skills, and intuition to make numerous inferences, both explicit and implicit. Without these inferences, it is fundamentally impossible to generate usable code.
However, several significant challenges make it difficult to build a model that can interpret UI designs like a developer. These include:
- The large and ever-increasing diversity in types of UI components and their visual appearance.
- Lack of standardization in how different UX designers create designs for the same purpose - there can be hundreds of permutations of elements and their groupings/ properties to achieve the same visual output.
- Designs are often imperfect and not precise to pixels. For example, the alignment of elements can be off by a few pixels, there can be layers not visible in design but still present in their vector design files, details of repeated elements can be different from each other, etc. These happen because many of these do not look off to the human eye, and it'd take an impractical amount of time and effort for designers to find each instance of them and make them pixel-perfect.
- Even a single component may require several designs to explain all its states correctly. Many of them are inferred by the developers and are not explicitly present in the designs.
- Lack of high-quality design to code datasets with tagging between the design and code elements.
Previous work
Over the years, various attempts have been made across commercial, open-source, and academic projects to algorithmically understand UI designs and/ or generate code from them. However, to the best of our knowledge, none of them have reached acceptable thresholds of quality and generality or achieved widespread adoption among developers.
Researchers have tried to utilize object-detection-based methods to identify & code components from screenshot images. However, the reported accuracy of these methods is below the threshold of being practically useful. This can be attributed to a few critical challenges inherent to such methods:
- These models struggle with detecting shapes of varied sizes and complexity, ranging from small and simple UI elements such as icons to large and complex UI elements such as grids and tables.
- It is hard to ensure adequate representation of the large variety of types and styles of components that exist in real-world designs in the training datasets.
- Real-world designs are very different compared to app screenshots in content and exact appearance. For example, a table with hundreds of rows in a rendered web-app page may have only a few rows in the design file. Or, the specific application state captured in a screenshot may vary significantly from the state(s) likely to be present in its real-world design file.
- These models struggle to estimate modern CSS properties needed for fluid/ responsive UI, such as flex, padding, gap, etc., from fixed dimensions that exist in images.
- It is difficult to accurately identify pixel-perfect appearance details, such as shadows, fonts, opacity, etc., from images.
The multi-modal LLMs that take images as inputs can provide excellent high-level descriptions of image inputs. However, they do not have the accuracy, subject relevance, or precision required to produce useful code for real-world projects from rich modern designs with tens of components per screen. While some multi-modal LLMs have been shown to produce prototype code from back-of-the-envelope mockups, we are unaware of any approach, either in commercial, open-source, or academic projects, that can get LLMs to solve the aforementioned challenges and work with real-world UI designs.
Text-based LLMs, such as ChatGPT, have demonstrated the ability to generate code from simple, high-level instructions, such as "suggest React code for a card with a red background." With adequate “prompt engineering,” such codes can be useful for obtaining boilerplate code and business logic for common functionalities. However, it is humanly impossible, or at least impractical, to write prompts that detail every visual and layout element required to code a modern UI design accurately. As a result, such models and applications are not useful for generating UI code.
Some commercial and open-source tools have tried to generate code from designs by asking users to add significant additional information to the design, either in the design tools or in their proprietary products. Typically, these include specific tagging, grouping, or naming of elements as well as using auto-layout or other similar features to capture the structural intent of a design. The information added must be exhaustive and follow the specific conventions proprietary to specific products. In general, developers and designers find this approach to be impractical in terms of the time and effort required. They also report that the tools are only able to generate “spaghetti code,” often with fixed dimensions unsuitable for responsive/ fluid applications, even after adding a lot of the context manually.
Method
Kombai uses an ensemble of deep learning and heuristics models, each purpose-built for a specific sub-task of interpreting UI designs and generating UI code from the derived interpretation. These sub-tasks have been defined to emulate the implicit and explicit inferences made by developers while building UI code from designs. The models are trained on carefully collected, purpose-specific training datasets that include a large number of UI designs, HTML code obtained manually as well as in automated ways, mapping between various elements in HTML and design files, and a large diversity of UI elements across pages.
We have implemented several novel algorithms and processing steps to help the models capture various “human” intuitions while avoiding some common pitfalls of traditional deep-learning-only models. For example, they do not require very large data sets to learn real-world constraints. And they are robust and work iteratively - so they are not thrown off completely, even when they get a few constraints wrong.
Further, the models have been trained to have reasonable fault tolerance to intelligently understand the common deviations that happen in real-world design files. Below are a few examples of the kinds of deviations that Kombai tries to decipher “like a human”:
- Elements off from ideal alignment by a few pixels, either relative to each other or an axis.
- Unintended layers in the design, e.g., invisible elements and overlapping nodes
- Unintended fills or shadows over groups or grouping frames
Once Kombai develops an “interpretation” of a design file, it generates UI code via a series of sequential processes. First, it tries to imitate the logical grouping of elements in the design to form the div structure. Then, it tries to generate CSS with minimum hardcoded widths and margins to position these divs and tries to guess which elements may grow and shrink. Thereafter, it tries to break down the code into logical components and tries to name these components so they are easy to understand and reuse. It also attempts to detect loops and conditions and substitute variables in place of the static text so that these components can be used as seamlessly as possible
Kombai also uses public LLMs to improve some specific parts of the self-generated code before showing the final output to the users.
Capabilities
Kombai can work with real-world designs without requiring users to tag, name, or group design elements in any specific way or define the fluidity of the layouts in the design (e.g., using the auto-layout feature of Figma). Instead, it works on vector data obtained from the design tool and tries to create code based on what the design would “look like” to a developer.
Kombai produces high-quality output code in React as well as HTML & CSS. In general, the generated code is expected to have the following features:
Logical Div Structure (in DOM)
Irrespective of the component structure present in the design file, Kombai is capable of generating logical HTML elements and their grouping.
For example, the following design file has a flat element structure without logical grouping. See Figma design here (opens in a new tab)
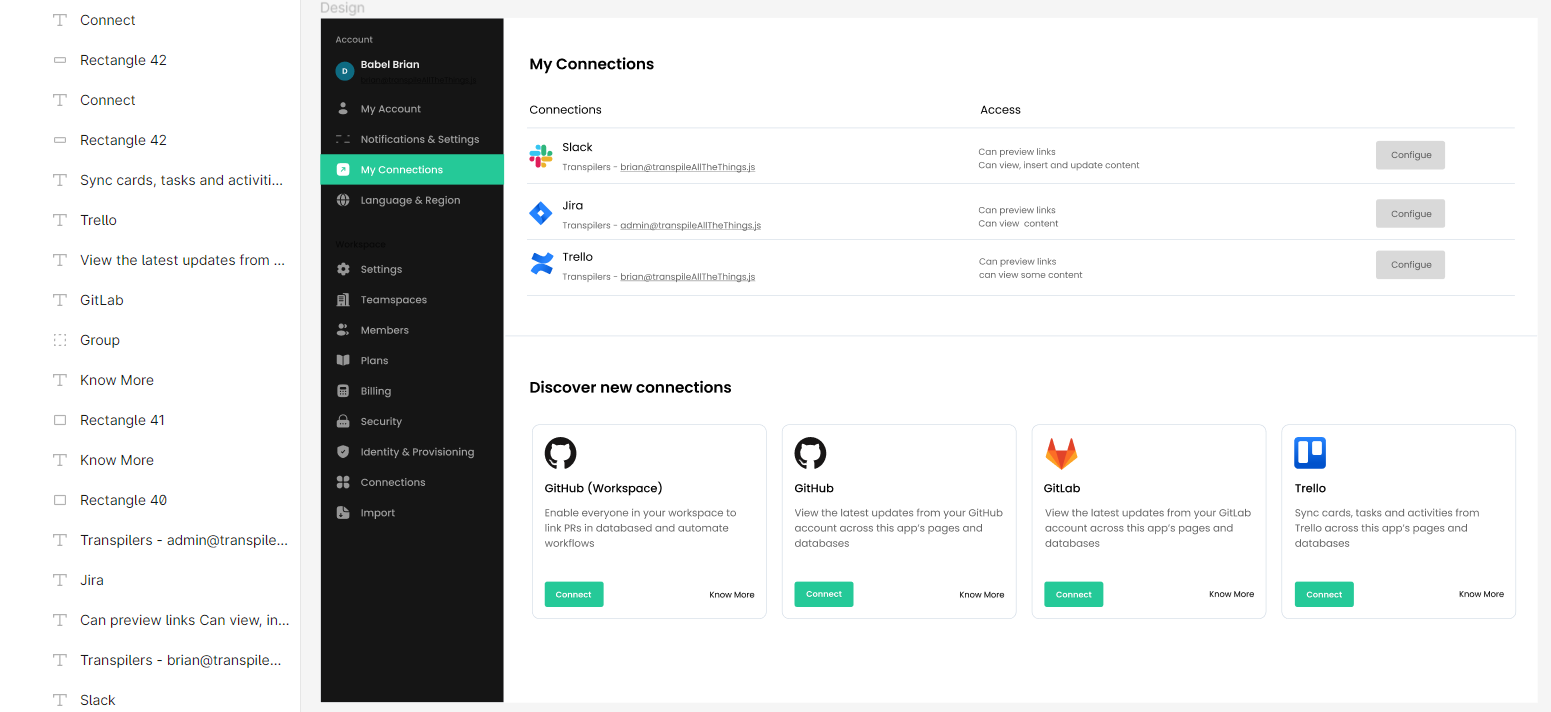
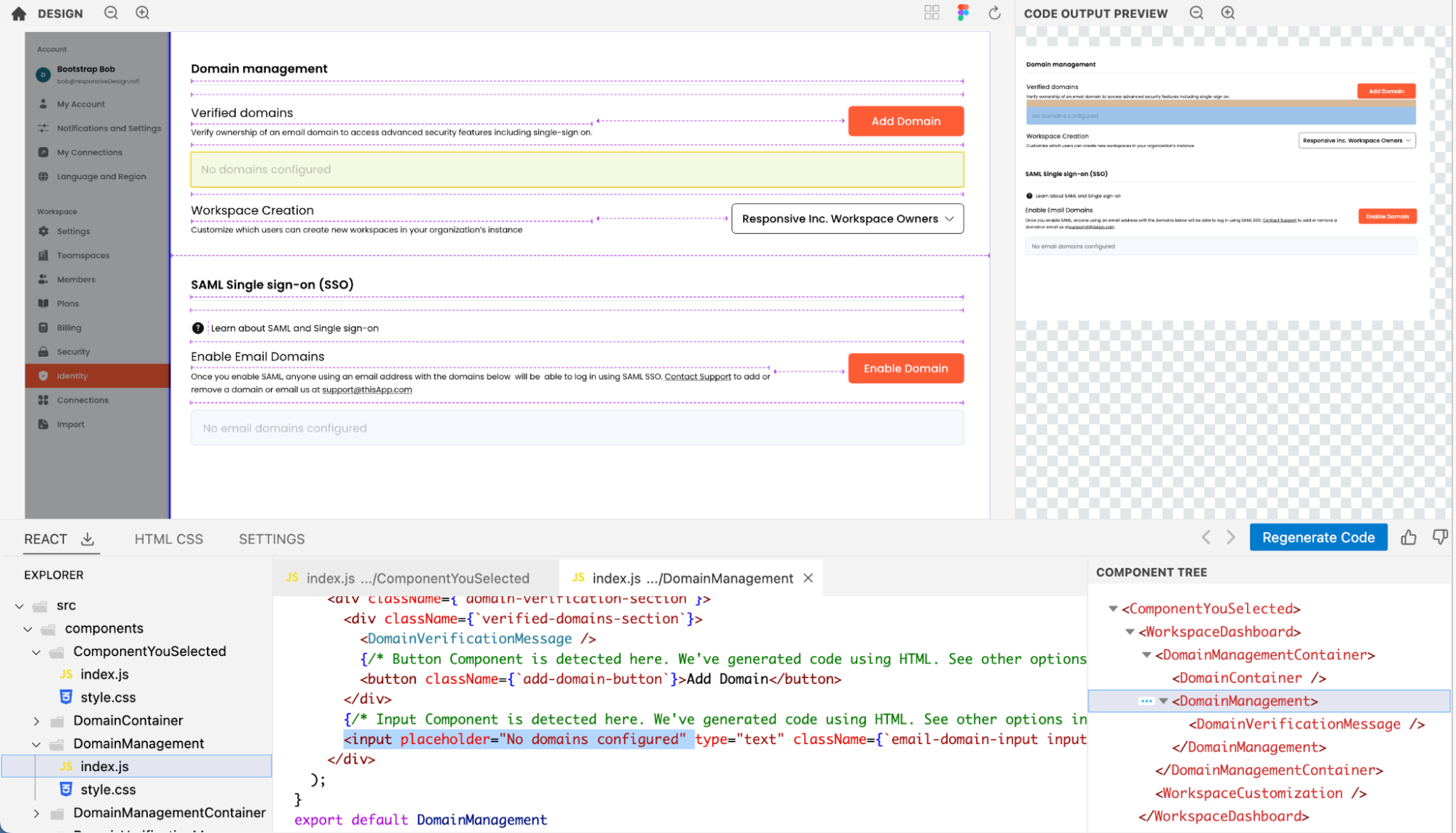
However, Kombai is able to figure out a logical div-structure for this, including a semantic table, as can be seen in the screenshot below:
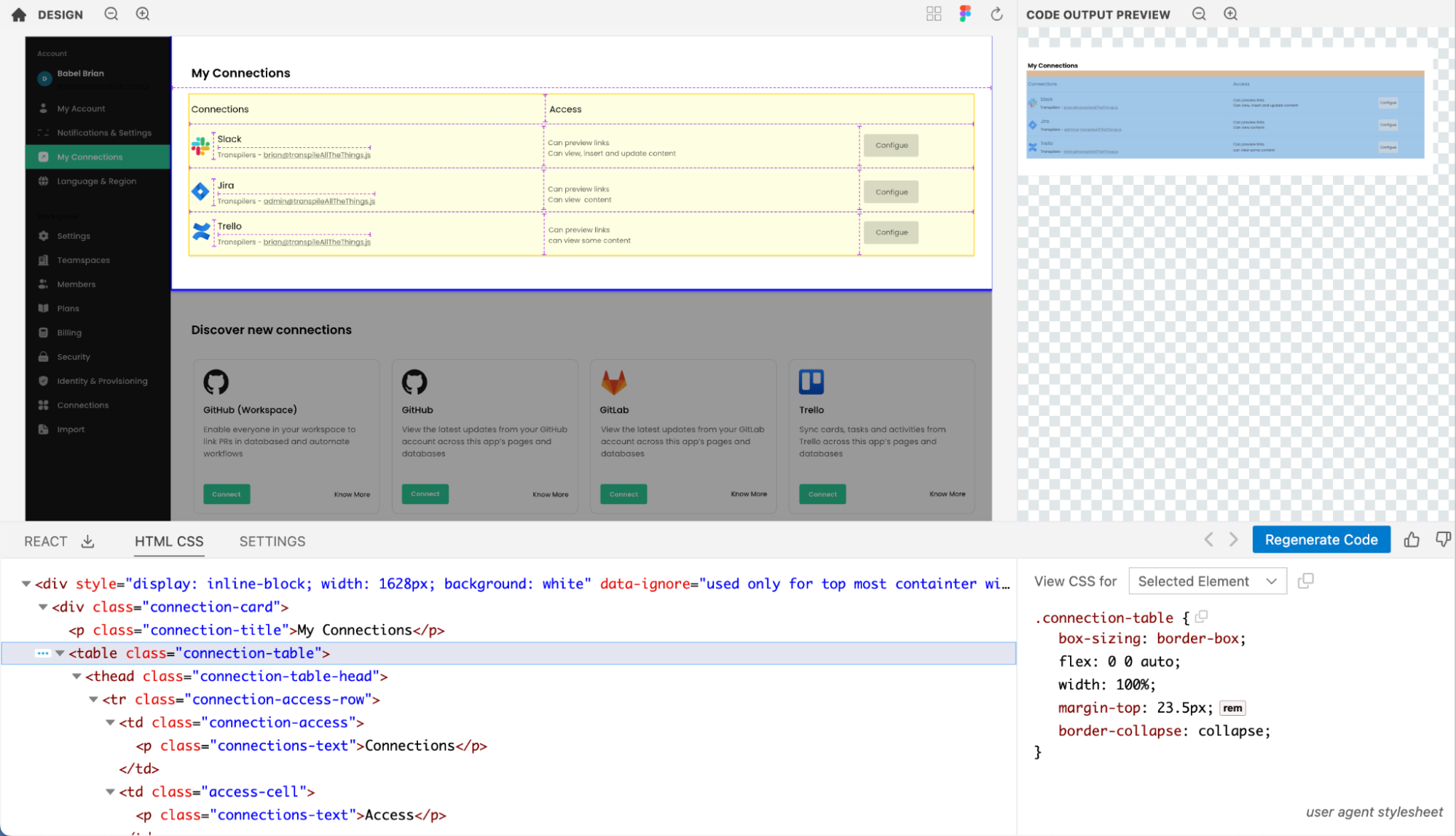
Open design in Kombai (opens in a new tab)
Logical component structure (in React code)
In addition to the div-structure in DOM, Kombai can also break down the React code into logical components. We can see an example of this if we select the bottom part of the main pane in the design above. See a screenshot below of the generated component structure for the design mentioned in the previous section.
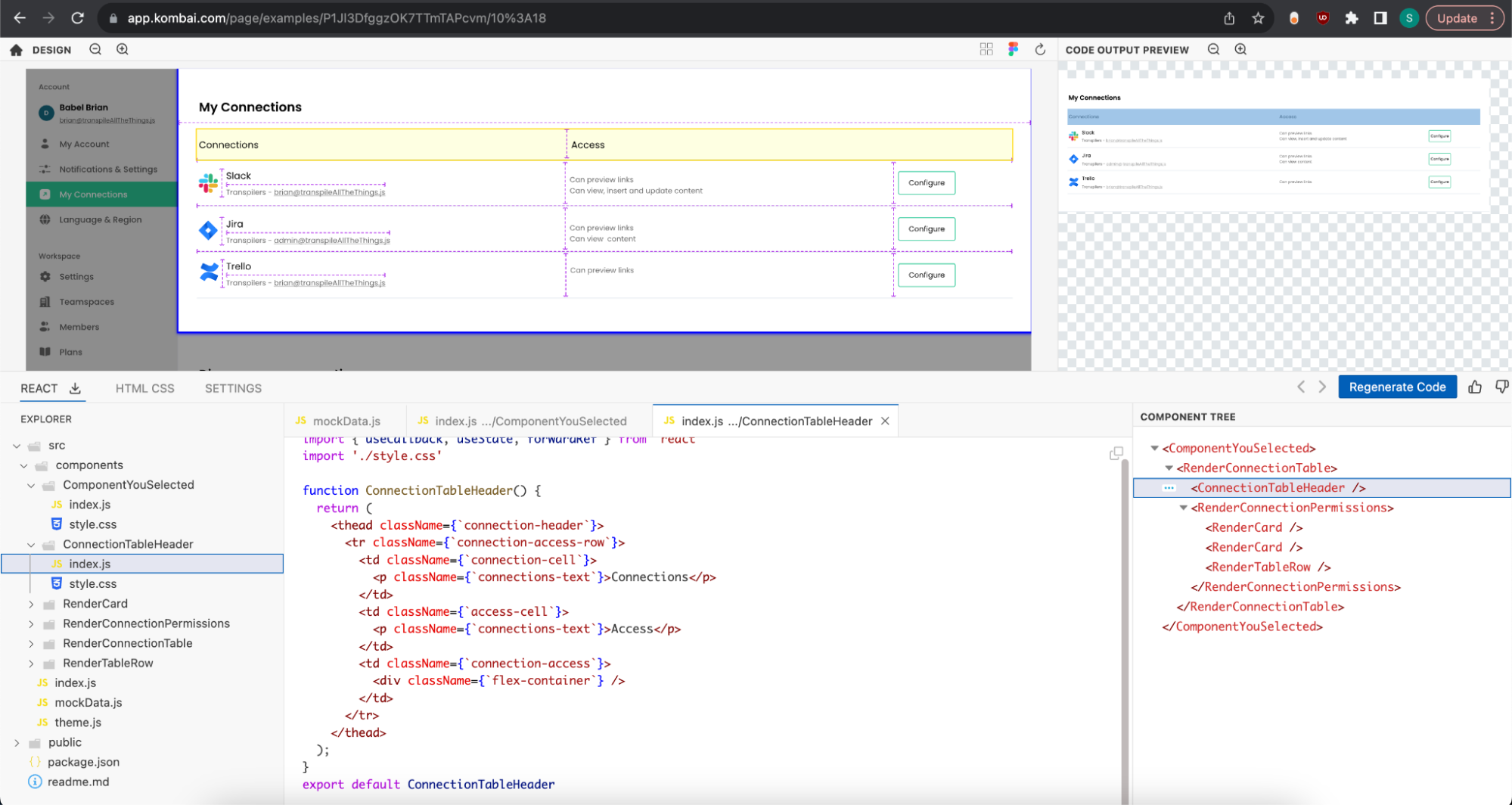
Logical names for classes, variables, and components
In addition to building the components and classes logically, Kombai can also figure out appropriate names for them based on their content. This does not require users to name their Figma elements in any particular way. You can see examples of this in the screenshots in the last two sections, e.g., Kombai was able to name the class applied to the table with the “ConnectionTableHeader” header as “connection-header.” Open design in Kombai (opens in a new tab)
CSS with no hardcoded dimensions and accurate width, margin, padding, and flex-related properties
Kombai can figure out the appropriate CSS needed to create responsive UI, such as flex-grow, flex-shrink, justify-content, align-items, align-self, gap, and padding. It creates a top-level div with fixed-width in order to ensure visual fidelity of the output, but you can easily exclude that while incorporating the code in your codebase. This doesn't require using auto-layout or grouping in the design file.
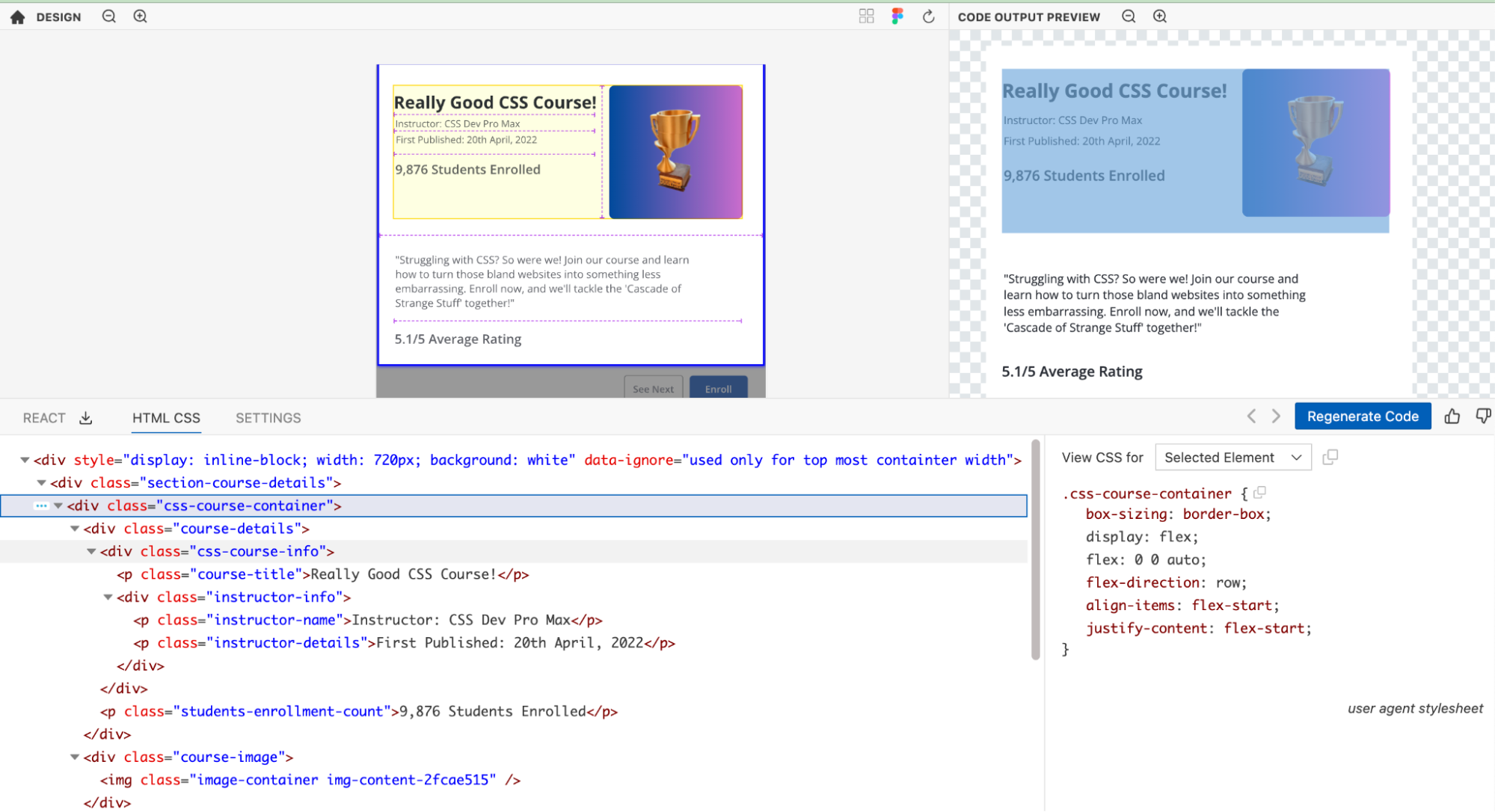
For example, let's consider the card shown below. Open design in Figma (opens in a new tab)
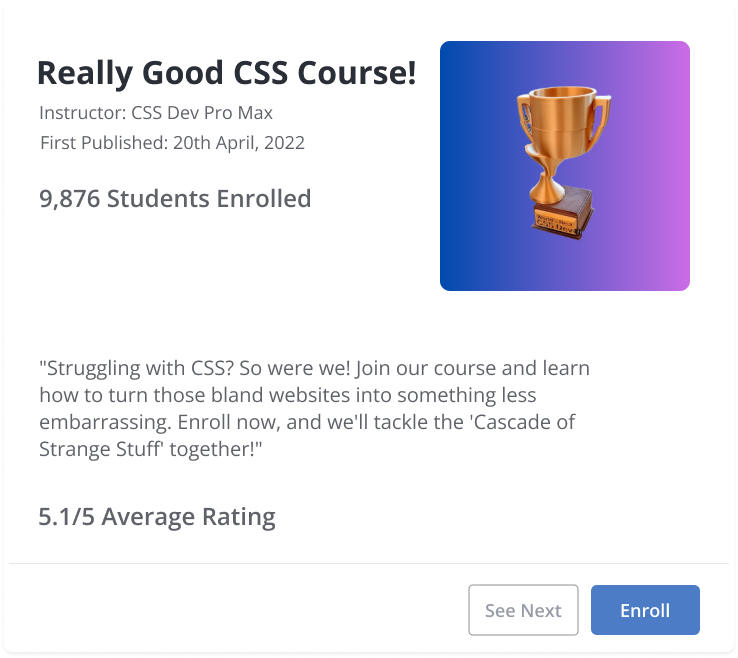
Kombai is able to figure out the appropriate CSS for this without any additional input from the user. Open design in Kombai (opens in a new tab)
Clean JS code with loops and conditions
Kombai is able to identify repeated instances of the same component, even when they have different content in the design. In such cases, it's able to create appropriate loops and conditions to create clean JS code.
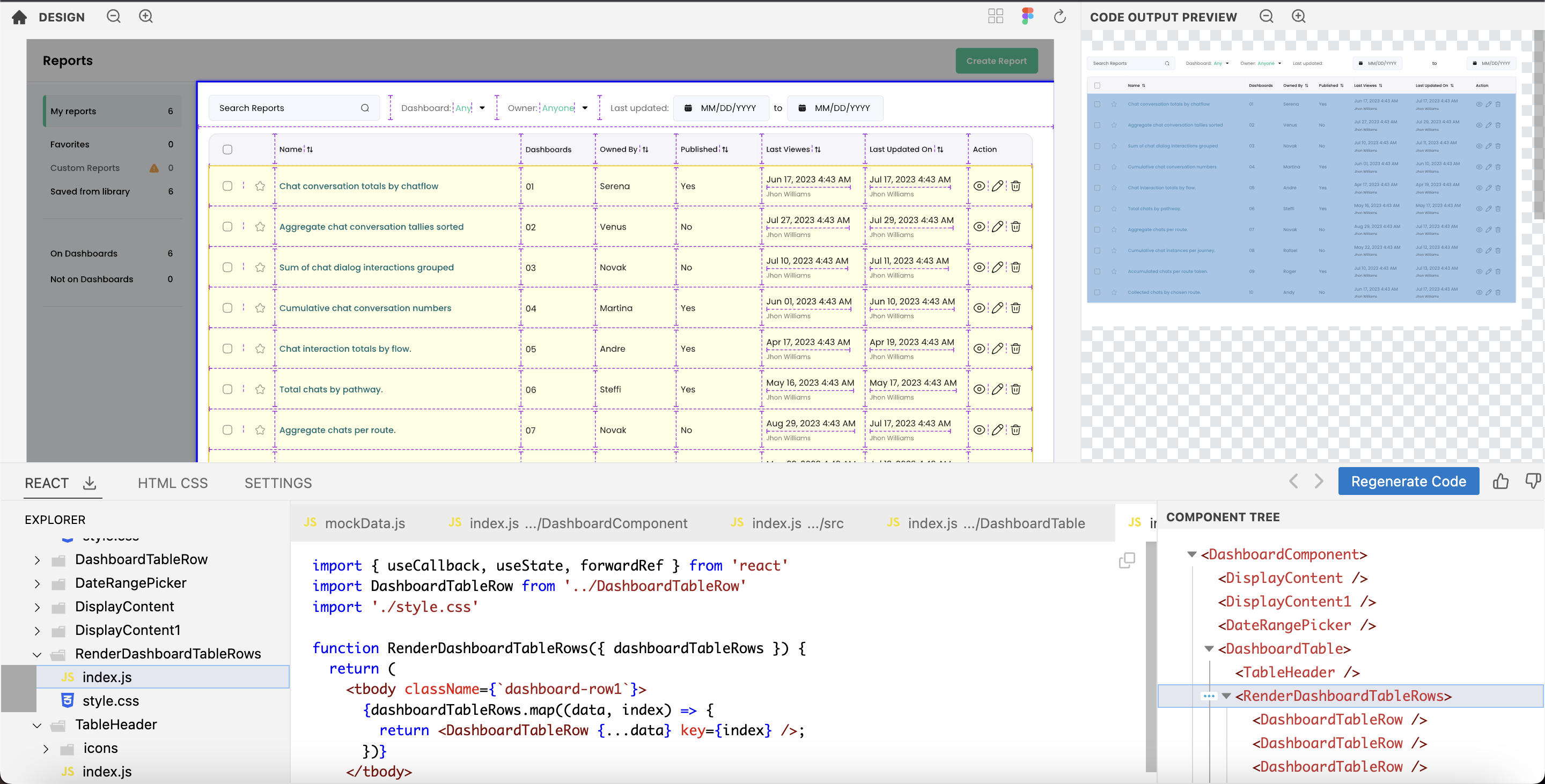
For example, here is a design of a table. Open design in Figma (opens in a new tab)
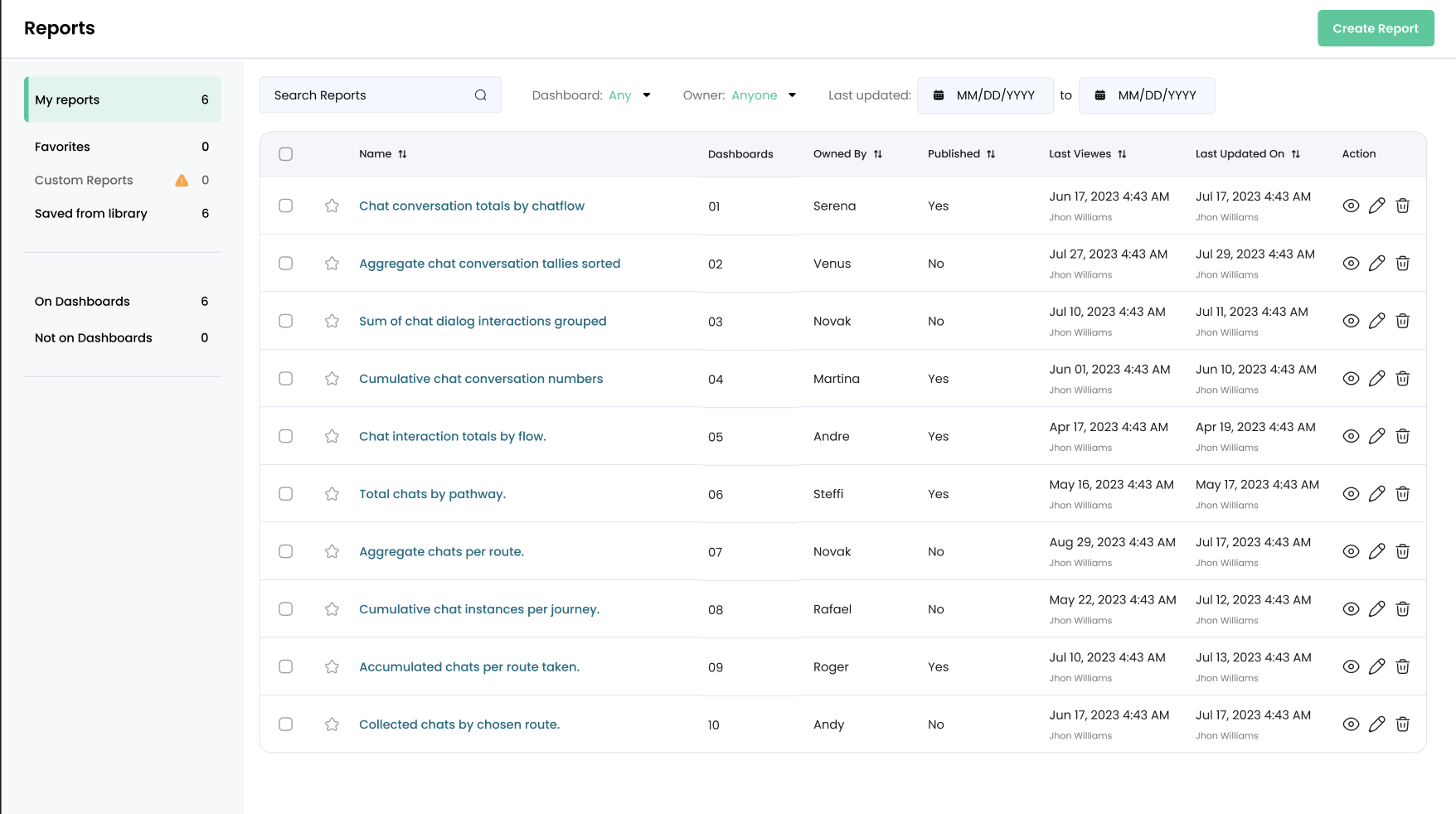
Kombai is able to create the rows of the table with instances of a single component. Open design in Kombai (opens in a new tab)
Functional components for form elements
Kombai can identify commonly used form elements such as buttons, inputs, selects and checkboxes and output them as functional components. By default, it uses compatible components for MUI Base, a headless component library. However, users can change settings for “component library” to “vanilla HTML/ JS” to get code output using native HTML components, as well. Kombai infers these components from their appearance, in the context of the whole page. This doesn't require the components to be marked or named in any way, in the design.
For example, the design below has a couple of inputs and buttons. Open design in Figma (opens in a new tab)
Here, Kombai is able to identify the input fields and buttons and generate functional components for them. Open design in Kombai (opens in a new tab)
Limitations
As a generative model, Kombai doesn't follow strictly rule-based boundaries. At times, it can produce incorrect outputs, particularly in cases where
- The design is ambiguous, i.e., there are not enough visual cues in the design for Kombai to derive the right inferences with high confidence.
- There are “unnatural” deviations in the visual aspects of a design, e.g., spacing and alignment, by a margin bigger than the models' acquired fault tolerance.
Below are some of the issues that are known to occur occasionally in Kombai's code output.
- Incorrect div structure - Kombai may incorrectly group elements. This may happen due to fewer cues in the design, such as borders or separators, or stacked elements being off from the axis by a margin greater than the models' tolerance.
- Incorrect alignment of elements inside flex - Kombai may incorrectly guess flex-justify and flex-align value for an element inside a flex. This may happen due to inconsistency or ambiguity in the spacing between an element and its parent or its alignment with its neighboring elements.
- Incorrect application of percent width - Kombai tries to apply space-between or space-around when it sees large margins between flex items. Otherwise, it defaults to percentage widths, which it may guess incorrectly. This may happen due to the model failing to group items together correctly or unequal margins between the items beyond the model's tolerance.
- An element appears either larger or smaller - The model may incorrectly guess the values for flex-grow and flex-shrink, or it may have failed to apply a min-width (if it appears shrunk) or may have failed to apply a max-width or flex-shrink if the content overflows.
- Incorrect component detection - The model may make a mistake in recognizing a form element or falsely recognize a similar-looking element as a form element.
- Incorrect handling of some vector images - Sometimes, the model may fail to group nearby vector nodes into a single SVG image. This can happen when all such vector nodes are not included in the same parent group.
- Undesirable absolute position in code - In rare cases, Kombai may generate code with a few undesirable absolute positions. This typically happens when the design contains overlapping nodes which the model cannot filter out. Often, these are unintentional layers remaining from a copy-paste or delete operation that happened while building the design in the UI design tool.
Steerability - “Design Prompt Engineering”
In general, Kombai is highly steerable. If Kombai makes incorrect inferences or generates code in a way that differs from users' preferences, users can make small adjustments to their designs to guide the model to rewrite the code in their desired manner. This process is similar to "engineering" text prompts for an LLM like ChatGPT or Claude. Therefore, we refer to this process as "Design Prompt Engineering."
Once the design updates are made in the design tool, users can choose the “reload design” option on the UI of the Kombai app to trigger the regeneration of code.
Here are some examples of how the users can engineer their design prompts to nudge Kombai:
- Add a line to tell Kombai about a section division
- Add a box to group elements of a section together
- Adjust the spacing between elements to reflect the true intention of the design
You can see this doc on “Design prompt engineering” for more details and examples.
Conclusion
During our private-research preview phase, developers have seen Kombai generate generally high-quality, logically structured code. Now, we are opening up the public research preview of Kombai to get feedback from the broader developer community and learn about its strengths and weaknesses. We'll leverage these learnings to continue to improve Kombai's capabilities with the aim of making it faster and easier for developers to build UI.